目標
概述一些我接觸過的一些套件,讓大家對爬蟲的「技術鍊」、以及「常見的問題及其解決方式」有基礎的了解。
動機
這篇文章主要是寫給剛開始學習Python爬蟲的初學者,由於自己剛開始學習這部分知識時,所有的套件名詞猶如雪片般飛來,有時會錯誤的理解一個套件的使用方式,有時則對某個套件期待過高,學成時總覺得不過爾爾,有種失落感。因此著述。
本篇文章的「爬蟲」
為了避免概念混淆,先打個預防針,我接下來要介紹的爬蟲,並非大規模的、地毯式的爬取任何可以取得的網頁,而是有針對性的爬蟲。也就是說,我在進行網頁爬取時,一般都會在同一個domain之內(網址中”http:/ /“後,第一個”/“符號之前的字串),同時會先鎖定我要爬取的幾個頁面,並進一步鎖定每一個頁面中我要取得的資訊,然後最後會用相對精準的方式整理資料存入資料庫。
爬蟲的架構
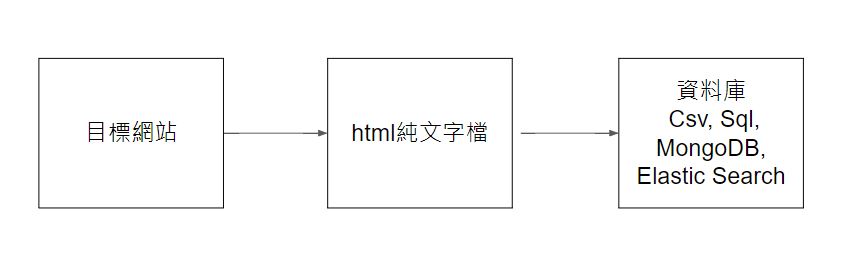
- 取得html檔: 由於每個網頁都是由html檔所構成,因此,取得html檔也就取得了頁面上可以看到的所有資訊,只是包含了很多你不要的雜訊。
- 解析html檔: 把上面取得的html檔中的雜訊去掉。由於html檔是給瀏覽器解析的,如果你直接去看html的純文字檔會非常辛苦,你可以現在按下F12試試看你找不找的到你要的資訊,而這樣給瀏覽器解析的文檔主要由html tag(如div, a, span…等),因此這部分主要著重在取出html tag中有價值的資訊(如夾在tag中間的text,或是value屬性中的值)。
- 把取出的資訊塞入資料庫
取得html檔
要取得html檔,我們首先就必須了解,前端(瀏覽器)是如何跟每個網站的伺服器要資料,以下詳細說明。
Http動詞:
從RestfulApi的理論來說,目前一般網頁除了透過URL(網址)去取得網頁之外,都還會配上一個HTTP動詞,增加前端介面跟資料庫互動的彈性,大家有興趣可以看一下WIKI。
GET
一般在瀏覽器上輸入URL進入網頁都是預設為GET動詞,就是純粹從資料庫中取出資料。
POST
POST動詞則是送出一筆表單資料,比較常見的出現地點是各位在申請帳號,輸入完資料之後按下提交那一刻,瀏覽器除了會自動重新轉向新的URL外,還會配上POST的動詞,如此則會回傳一筆表單資料伺服器,然後再進一步導向「申請成功」的介面。而這兩個動詞也是爬蟲領域當中比較常用到的,其他動詞若各位對架設API有興趣,可以自己再去學習。
需要特別提醒的是,因為POST是送出一筆表單資料,所以下面「用法」環節,也要傳送一筆python中dictionary型別的資料給伺服器,才能得到POST方法配上URL回傳回來的資料。
查看GET或是POST
至於如何進一步去查看,目前的網頁是透過GET或是POST而回傳的結果,則可以按下F12,點到Application(如果是空的,可以按一下F5重新整理),並透過每一份文件中的Preview進一步確定回傳的文件中哪一份是你要的,然後再點回Header去看,Request Method後面是GET或是POST。


套件與使用方法
主要使用套件: requests(早期用urllib):
其實我不太清楚這兩者的差異,但至目前為止,我遇過的所有網站,都可以透過requests來處理。
使用方法
|
|
實務問題一: encoding問題
如果發現爬下來的的頁面無法解析的話,大部分時候是編碼的問題,編碼一般都是用utf8,這個包含的字量比較多,例如「喆」在其他編碼中一班會用「吉吉」儲存,不過比較老舊的非英文網站,或是政府官方網站,如果是中文的話很可能會使用cp950或是big5,這個編碼一般都是從html文件中(所有的html文件都有head跟body兩個部分)的head部分找得到,按下F12找到Elements。
狀況一: 爬下來的html檔是亂碼
這種狀況可直接設定requests類別實體下的encoding屬性為相對應的編碼,上面「使用方法」中已經有使用過,就不再贅述。
狀況二: POST Data是亂碼
如上圖(Post Data)中的qCollege欄位的值即是亂碼,此時點擊此途中右上角的view URL encoded,並複製編碼下的字串到webatic去解碼,了解這個編碼背後的意思。
實務問題二: 檔案讀寫問題
若不先將html存成純文字檔案,有可能會產生兩個大問題。第一、電腦的記憶體有限且相對不穩定,所以如果把每個頁面都用暫存存起來,可能會產生記憶體不足,或是程式執行出錯時暫存全部被洗掉的問題。第二、如果每次測試解析html之前都要上網站去get一次,兩大的話很有可能會被鎖定IP。因此,檔案讀寫是爬蟲過程中不可或缺的一項技能。使用的套件是python內建的套件open,我們直接承接上面的re.text字串,進行以下示範。
實務問題三: 一般網站的防爬蟲機制
因為網站的防爬蟲機制,一般都是在requests的階段會碰到問題,所以就在這部分講一講,比較常遇到的一些問題,以及他的解決方案。
直接偵測requests的header

這個header可以透過F12>Network>目標頁面>Requests Headers找到,這個東西如果你是用python的requests套件,伺服器端偵測到的可能就是Python用戶端送出的requests,有些防爬蟲比較高階的網站會檔下這類型的requests,因此如果有遇到這類問題,可以這樣處理。
如果各位不相信,可以把假header拿掉試試看,然後在回傳的值當中,尋找這個網頁最重要的元素(ctrl+F)$259,123,照理說你透過python得到的網頁,跟直接透過瀏覽器接點進去的就不是同一網頁了,應該會是她特別寫給爬蟲愛好者取得的一個網頁,你也就找不到這個數字了。
一秒太多次requests
由於大量爬取同一個網域的網站,剛開始我們都會直接透過迴圈處理,但是迴圈一般都會以比你想像中快十倍甚至百倍的速度運行,也就是說,一秒內你可能發超過10個requests給那個網站的伺服器。而恰巧不巧,早期攻擊一個網站最常使用的方式就是大量送出封包癱瘓伺服器,但是現在這部分的攻擊基本上都已經沒有效果,每一種語言的網站架構基本上都會有預設防禦這種類型的攻擊,就算開發人員沒有特別注意,也會預設擋下這類型的requests。所以建議你,如果要大量發出請求,可以使用time這個套件。
總共太多次requests,或太規律,鎖IP
重複向特定網站的伺服器送出過多requests時,網站可能會直接鎖定你現在所使用的IP位置,這個時候也只能想辦法換IP拉,有幾種換IP的方式,因為你的手機一般都是浮動IP,所以如果流量夠的話,可以重新連線一次,一般wifi也是同樣的原理。不過有時候,這樣做如果間隔時間太短,系統還是會使用同一組IP。
這邊介紹一個小工具給大家,原本是我去大陸時,翻牆回來的工具,後來發現爬蟲上使用更是便利,而且如股純粹是爬蟲用途的話,你可以不必使用付費的版本。就是hotspotshield,當然大家如果有習慣使用的VPN工具,那也是可以啦,這個工具的使用上,一但你發現你的IP被封鎖了,直接重新連線hotspotshield,它就會幫你換到其他國家的IP了。
順帶一提發現IP被檔的辦法,我很習慣性的會先把抓下來的html文件存成一個個的純文字檔,在程式在跑的過程中,你可以打開檔案總管到你儲存純文字檔的資料夾中,監視檔案的大小,一旦發現檔案的大小都維持在同一個且很低的水平的時候,大約就代表你被封鎖IP了。當然你也可以透過python去偵測純文字檔儲存下來的大小,如果規模夠大的話,還是很有效益的。
實務問題四: javascript渲染出來的網頁,或不明原因被檔的網頁
由於現在網頁技術越來越先進,往往很多網頁的內容,並不需要透過獨立的網址才能呈現,在同一個網址下,透過javascript就可以讓html元素做很多變換,在配上ajax甚至可以跟資料庫互動。因此,若你要取得這些,進入網頁與使用者互動之後才會得出的html元素,純粹的requests就無法滿足你的需求了。
也因應這個網頁設計越趨複雜的趨勢,現在網頁測試的領域也越來越興盛,因此selenium這一個網頁自動化測試工具也就誕生了。它實作了非常多的介面,當然其中也包含python。從爬蟲的領域來看,這個東西就是個神器救星,因為所謂網頁測試,也就是要模仿真人操作網頁的行為進行測試網頁是否有bug,
換而言之,真人透過與網頁互動用javascript產生的html元素這時也可以輕易取得了。另一方面,由於不太可能有網站可以區分自動化工具跟真人,一旦它擋下你的自動化測試工具,它擋到真的人的機會也會很高,會很不利它網站的運作。總體而言,這還是一個滿方便的爬蟲工具。
這邊簡單說明一下selenium使用的過程中要注意的問題:
- 無論使用哪一個瀏覽器,都要使用webDriver,如Chrome Driver
- 我習慣透過Selector或是Xpath定位元素
- 再對任何元素做動作的時候,最好要設定保護機制,如果元素還沒出來,將無法定位到元素,後面的操作也不會成功
- 要取得當前頁面的html,使用的是page_source這個屬性的值1234567891011121314151617181920212223242526from selenium import webdriverimport timedriver = webdriver.Chrome() # 如果你沒有把webdriver放在同一個資料夾中,必須指定位置給他driver.get("https://timetable.nctu.edu.tw/")def tryclick(driver, selector, count=0): ##保護機制,以防無法定味道還沒渲染出來的元素try:elem = driver.find_element_by_css_selector(selector)# elem = driver.find_element_by_xpath(Xpath) # 如果你想透過Xpath定位元素elem.click() # 點擊定位到的元素except:time.sleep(2)count+=1if(count <2):tryclick(driver, selector,count)else:print("cannot locate element" + selector)tryclick(driver, "#flang > option:nth-child(2)") # 設定成中文tryclick(driver, "#crstime_search") # 點擊「檢索」按鍵time.sleep(3) # 等待javascript渲染出來,當然這個部分還有更進階的作法,關鍵字是implicit wait, explicit wait,有興趣可以自己去找html = driver.page_source # 取得html文字driver.close() # 關掉Driver打開的瀏覽器print(html)
解析html檔
在解析html檔時,我們首先需要了解兩個概念,第一個是html標籤,這個部分也是組成網頁的最主要部分,第二個是定位html標籤的方法selector以及Xpath,這兩個工具可以幫助你在html檔中快速找到你要的網頁資訊。
html標籤tag(元素element)
這個部分我只說幾個重要的元素,這部分如果是html的初學者,必須注意每一個tag的功能,在爬蟲的應用上通常會特別注意「是否為表單元素」,如果是表單元素,有價值的資訊並不像其他元素,用一組html tag包起來,而是放在tag中的value屬性。其他,比較詳細的教材,可以看W3school。
標題(h1~h6)
12<h1>This is a heading</h1><h6>This is a heading</h6>段落(p)
1<p>This is a paragraph.</p>連結
12<a href="http://www.w3school.com.cn">This is a link</a># 注意href是a元素的「屬性」,裡面的網址若沒有http開頭,一般都是使用跟你所在網頁相同的網域(domain),詳見下面的圖片解釋。頁面分割用元素
12<div></div>#這幾年比較新設計的網頁,一般都是使用這個元素做頁面分割的,雖然本身不含有重要的資訊,但是在定位元素時,會很常需要繞過div圖片
12<img style="padding-top:112px" height="92" src="/images/branding/googlelogo/2x/googlelogo_color_272x92dp.png" width="272" alt="Google" id="hplogo" title="Google" onload="google.aft&&google.aft(this)"># 此圖片中的img使從google首頁擷取下來的,style, height, width...都是這元素的屬性。而google的網域是https://www.google.com.tw/,因此你可以透過https://www.google.com.tw/images/branding/googlelogo/2x/googlelogo_color_272x92dp.png,找到google標誌的圖片,

- 表單元素: 這個地方要比較注意的是,一般表單元素中有價值的資訊都存在value當中,而不是一對tag的中間。12345<form><input type="text" name="firstname"><input type="radio" name="sex" value="male" checked>Male<input type="submit" value="Submit"></form>
表格元素: 這是表格元素的架構,一個比較正規的html table應該要以這個架構去寫成,大家可以多把焦點放在整個朝狀結構每一格tag的名稱。
12345678<table><thead><tr><th></th><th></th></tr></thead><tbody><tr><td></td><td></td></tr></tbody></table>大家可以直接上去這個網頁(公開資訊觀測站)按F12中element看看,這裡就不演示了。
Selector以及Xpath
上面講了主要組成網頁的基本元素,接下來要講的是,讓電腦可以找到特定元素的方法。這邊只簡單講概念,詳細部分,selector請看W3school,Xpath請看W3school。
Selector:
這個部分因為實在太複雜,只說幾個重要的,我知道大家看完還是霧煞煞,別著急,下面我們會跟著python套件一起示範使用方式。
- 元素名稱: 所有是這個名稱的元素
- class: 用”.”代表,一般一個html頁面中多個html元素會共享一個class
- id: 用”#”代表,一般一個html頁面中每個html元素的id是不會重複的
- 空白建: 代表在某個元素下面尋找全部
- “>”: 代表尋找下一階層的元素
舉台北大學課程檢索頁面為例:
進入頁面後按下F12,如果是使用chrome,左上角會找到一個元素選擇器,透過選擇器去網頁上面點選特定的元素,瀏覽器就能自動幫你定位出他在html中的位置。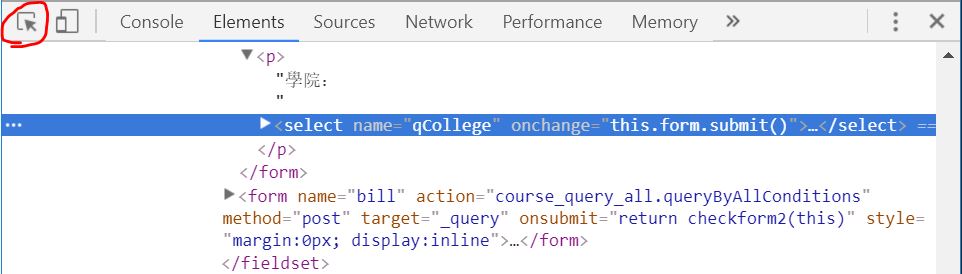
此時,在元素上面點擊右鍵>copy>copy selector,就可以取得這個元素的Selector:
不過請注意,nth-child這個功能在下面要介紹的拆解html的python套件BeautifulSoup中並沒有被實作,也就是這個套件無法處理這樣的語法,因此必須透過其他解決方案,來處理這個元素。
Xpath:
這個概念就比較簡單,html檔案是巢狀結構,也就是一層包一層的結構,最上層的結構就是html,然後html裡面會包著head跟body,網頁中通常會直接被你看到的部分都包在body中。下面可能就會有很多div, h1~h6,或其他上述元素。
而所謂Xpath,就是透過,從最上層到最下層。每一層經過的tag名稱串接起來的定位器,承上例,將copy Selector改為copy Xpath即可得到:
應用套件BeautifulSoup、pandas
非表格元素: BeautifulSoup
首先必須說明的是,這個套件的底層是用正規表示式所寫成,早期一點的爬蟲玩家,大都必須比較辛苦的手刻正規表示式,現在大家就比較方便拉,詳情大家可以看他們的官網,以下我僅針對比較常用的幾個元素做簡單示範。
表格元素: pandas
如果對於數據處理有興趣,非常推薦認真學一下pandas,這東西就是python中的excel,功能非常強大,解析html tag只是其中的一個小功能。
持續發展
如果你對這個技術有興趣,你未來除了可以持續熟悉上述提及的套件之外,以下也會給你一些進一步學習的方向,也很期待你們可以留下一些反饋:
- 資料庫技術: 比較常被使用的免費關聯式(SQL)資料庫 MySQL(收費的部分,業界比較常使用的是MS SQL),非關聯是(NoSQL= Not Only SQL)資料庫 MongoDB。
- 非同步技術: 相對大規模爬取網頁時,asyncio, aiohttp 可大大加速爬取的速度,有興趣可以看我的另一篇文章。
- 大規模有架構的爬取技術scrapy: 這東西的架構要花一點時間了解一下,又是另一篇文章要解決的事情了,有興趣自行研究吧。只說一個點,就是setting中的ROBOTSTXT_OBEY記得改成False。