
MCP全稱叫做Model Context Protocol,基本上就是一個讓模型有操控電腦App的橋樑,雖然網路上討論很多,但是大多都是簡單的使用教學,沒有比較深度的討論。這篇文章希望可以更深入的探討要支撐MCP,LLM應具備哪些能力,目前開源模型可以做到什麼程度,以及目前有哪些推薦的MCP工具,未來可能的發展方向是什麼。
這篇文章主要說明以下幾個重點:
MCP的基本運作
Function Calling扮演的重要角色
使用建議書:
推薦的MCP Client
推薦的MCP Server
使用體驗較好的應用場景
Gemma 12B搭配MCP的使用心得
MCP的下一步是什麼
一、MCP的基本運作
(一)、參與MCP的四個角色
| LLM (Claude) | 大型語言模型,可以是雲端模型API,或是本地端模型像是Ollama。 |
|---|---|
| MCP Client (Claude Desktop) | 本地中介程式,負責與 LLM 互動,轉發請求給 MCP Server,並回傳結果。 |
| MCP Server (Application API) | 提供具體功能的 API,例如查詢狀態、執行操作,是工具的執行端。 |
| Application | 真正的應用程式或系統,MCP Server 對它發出請求以完成任務。 |
相信LLM跟Application都已經是我們熟悉的角色,至於Client-Server架構相信各位也已經聽很多,這邊只說明三點:
MCP Client (Claude Desktop):世界在LLM跟MCP Server的中介,如果你用Claude Desktop去操作MCP,那麼Claude Desktop就是這邊的Client。
MCP Client 跟Server的關係:每次執行Client時,他會透過子程序(sub-process)去打開Server。
MCP Client 跟Server的溝通:因為兩者大多是在同一機器上,又是透過子程序運行Server,直接透過OS內部的stdio去溝通即可。如果是遠端Server是透過SSE溝通,SSE這裡就不解釋了。
(二)、Claude MCP的運作流程
本段落的流程是按照Claude的官網給的示例進行撰寫。
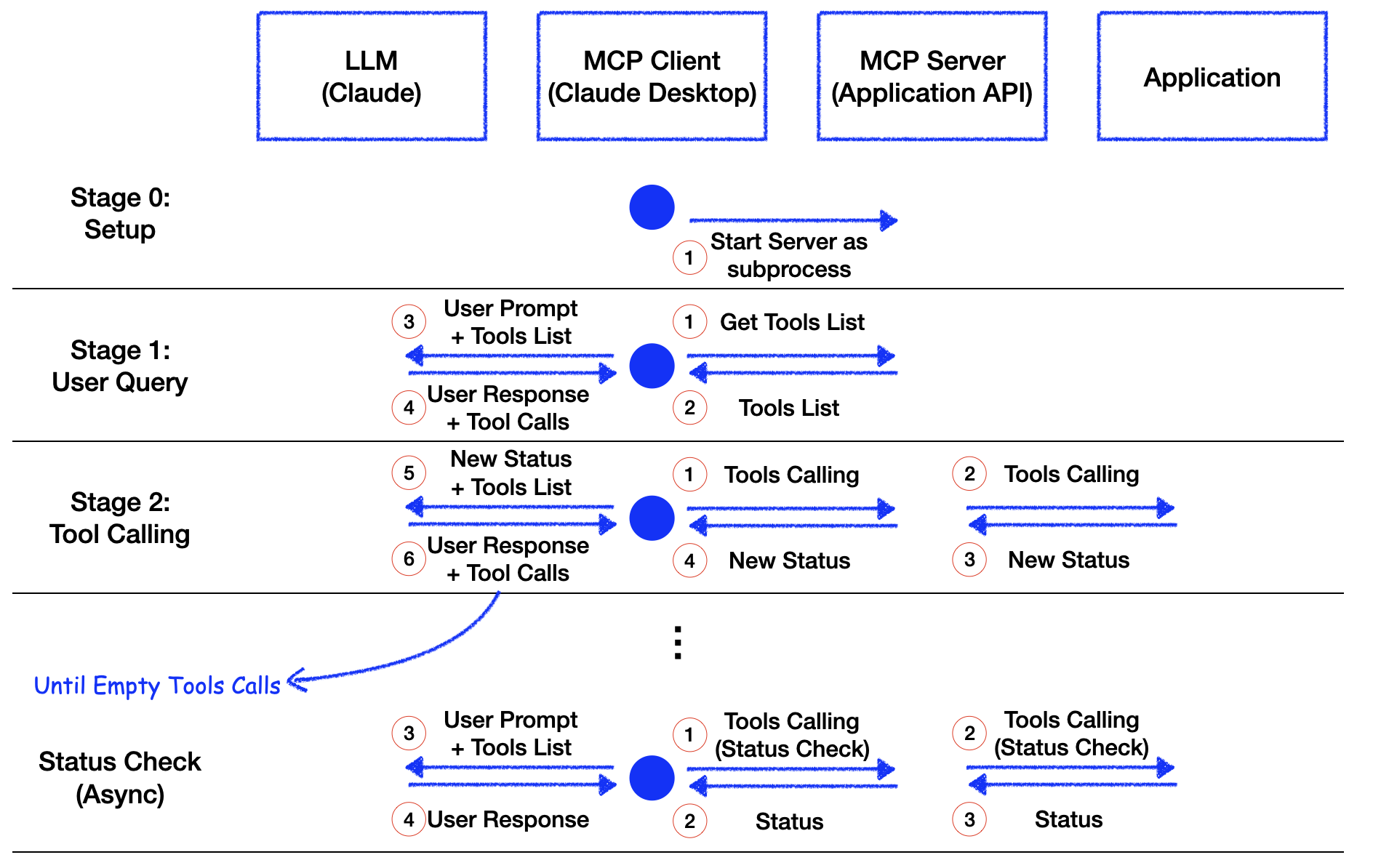
Stage 0:初始化(Setup)
- Client 以子程序方式啟動 Server,確保 API 可用。注意Client與Server使母子程序關係,並可以透過最簡單的跨行程溝通(Inter Process Communication, IPC)就是Standard IO (stdio)。
Stage 1:使用者提問(User Query)
Client 發送請求給Server取得可用工具清單: 為了讓 Claude 能知道有哪些工具可以使用,Client 向 Server 請求工具清單。
Server 回傳工具清單。
Client 將「使用者提問 + 工具清單(工具的名稱、描述與參數資訊)」 傳給 LLM。
LLM 會進行「多工具」與「多步驟」的規劃。
response = await self.session.list_tools() # 取得可用工具清單 available_tools = [{ "name": tool.name, "description": tool.description, "input_schema": tool.inputSchema } for tool in response.tools] # 工具清單 # Initial Claude API call response = self.anthropic.messages.create( model="claude-3-5-sonnet-20241022", max_tokens=1000, messages=messages, tools=available_tools # 將「使用者提問+工具清單」 傳給 LLM ) # example available_tools # [ # { # “name“: “get_forecast“, # “description“: “Get weather forecast for a location.\n“ # “\n“ # “Args:\n“ # “ latitude: Latitude of the location\n“ # “ longitude: Longitude of the location\n“, # “input_schema“: { # “properties“: { # “latitude“: {“title“: “Latitude“, “type“: “number“}, # “longitude“: {“title“: “Longitude“, “type“: “number“} # }, # “required“: [“latitude“, “longitude“], # “title“: “get_forecastArguments“, # “type“: “object“}, # } # ]
Stage 2:工具調用(Tool Calling),這個階段會不斷重複,直到 LLM 不再發出 Tool Calls,也就是整個任務的執行已經完成。
Client 根據 LLM 回覆的 Tool Calls,讓 Server執行特定工具跟參數。
Server 接到要求,執行對應的工具,與應用程式互動。
Server 回傳新的狀態(New Status)給 Client。
Client 將新的狀態再傳給 LLM,進一步產生新的 Tool Calls(如有)。
for content in response.content: if content.type == 'text': final_text.append(content.text) assistant_message_content.append(content) elif content.type == 'tool_use': # LLM指定的Tool Calls tool_name = content.name tool_args = content.input # Execute tool call result = await self.session.call_tool(tool_name, tool_args) # 執行Tool Call final_text.append(f"[Calling tool {tool_name} with args {tool_args}]") assistant_message_content.append(content) messages.append({ "role": "assistant", "content": assistant_message_content }) messages.append({ "role": "user", "content": [ { "type": "tool_result", "tool_use_id": content.id, "content": result.content # 將執行結果再回傳給LLM } ] }) # Get next response from Claude response = self.anthropic.messages.create( model="claude-3-5-sonnet-20241022", max_tokens=1000, messages=messages, tools=available_tools ) final_text.append(response.content[0].text)Status Check(Async)階段:因為所有MCP內部的Function都是用非同步實作,在Tool Call執行的過程中,使用者可以持續發送問題給LLM,去確認目前任物執行的進度。其流程跟前面一樣,這裡就不再贅述。
二、Function Calling扮演的重要角色
從上面的基本運作應該就可以理解,MCP最核心的關鍵還是Function Calling的能力,更細緻的理解實際上是三個基本能力:
指令遵循能力
我們都理解,LLM的可以接受的資料都是純文字,怎麼讓模型可以理解工具列表提供的資料結構,包含哪些工具可以使用、每一個工具的意義還有參數的設定。另外,在回傳值部分,如何透過指令強迫模型要生出符合格式的json檔,去指定要使用哪一些Function,分別要帶入什麼參數。
工具選擇能力
在具備多種工具的情境下,模型不只要能理解每個工具的功能與限制,還必須在特定任務中「選擇最合適的工具」來達成目標。這意味著模型需要判斷:某個需求是否可以純文字回答?還是必須透過外部函數?如果需要工具,它要知道要用哪一個工具、而不是全部都嘗試一遍。
多步驟規劃能力
在任務變得複雜時(例如要先分析再轉換,再回報結果),模型必須具備類似多步驟任務分解的能力。這不只是 Chain-of-Thought(思路鏈)推理,而是要能做到「工具調用的計畫編排」。像是遇到使用者輸入:「幫我找到MCP中送出使用者Prompt的程式碼所在的位置」,模型就要規劃成:
尋找檔案(search_files):
find . —name *.py讀取檔案(read_file):
catclent.py執行指令(execute_command):
grep -E 'completion|generation|create'整理成一行就會變成:
grep -En 'completion|generation|create' $(find . -name '*.py')
這些能力大多是LLM經過Instruct Fine-tuning才可以確保Function Calling的運作品質,雖然大多大廠的LLM API都已經有Function Calling的介面,如OpenAI、Claude、Gemini與Deepseek等都確定已經是在API函數等級的支援,但是開源的模型權重,則必須詳細的觀察他的文件是否原生支援Function Call,更難的是其「工具選擇能力」與「多步驟規劃能力」,Instruct Fine-tuning的品質是重中之重。
以gemma 3來說,雖然官方有提供Function Calling的Template,但實際上是直接把Tool List放進Prompt中,如下所示。順帶一提,Ollama的也是這樣使用Function Calling的。
You have access to functions. If you decide to invoke any of the function(s),
you MUST put it in the format of
[func_name1(params_name1=params_value1, params_name2=params_value2...), func_name2(params)]
You SHOULD NOT include any other text in the response if you call a function
[
{
"name": "get_product_name_by_PID",
"description": "Finds the name of a product by its Product ID",
"parameters": {
"type": "object",
"properties": {
"PID": {
"type": "string"
}
},
"required": [
"PID"
]
}
}
]
While browsing the product catalog, I came across a product that piqued my
interest. The product ID is 807ZPKBL9V. Can you help me find the name of this
product?
(一)、MCP 比Function Calling多了什麼?
雖然說很多很吸睛的應用在Function Calling時代就已經可以達成,但其實還缺一個重要的功能,就是自動的多輪對話直到把用戶的問題解決的能力。可以想像一個情境,如果是一個多步驟才能完成的任務。例如讀取檔案內容後,發現資料檔在另外一個json檔裡面,就要在執行一次讀取。
想像一下這個例子,「幫我找到MCP中送出使用者Prompt的程式碼所在的位置,並找到Tool List是用什麼格式送出」,當LLM找到了程式碼檔案的相關段落,發現使用者的關心的Tool List實際上寫在另外一個template檔案裡面,這時你就要根據程式碼的內容做進一步的搜尋跟讀取,如此一來才能夠提供給使用者真正關心的答案。
| Functional Call | MCP | |
|---|---|---|
| 指令遵循能力 | V | V |
| 工具選擇能力 | V | V |
| 多步驟規劃能力 | V | V |
| Multi-Round Communication | X | V |
| 非同步進度確認 | X | V |
總的來說,MCP比起Function Calling,真正的價值是在提供一個溝通環境,讓程式跟LLM可以保持溝通,並多輪對話確保可以最終解決問題。另外,因為實作上MCP所有的Function都採用非同步的實作,所以他允許較長時間的Function Calling,並讓使用者在等待時可以持續跟LLM進行對話,如確認長時間執行程式的進度;而MCP Server有任何狀態更新也可以傳送訊息到MCP Client的介面上。
(二)、更詳細的看Function Calling的原始運作
下圖是OpenAI提供的Function Calling流程圖,OpenAI提供的原圖是在呼叫一個查詢天氣的功能的函式,但我們把任務設計的複雜一點,假設我們正在用一個可以控制traminal並可以讀寫檔案的工具庫desktop-commander。假設我們寫一隻程式問LLM:「幫我在MCP的repo中找出送出使用者Prompt的程式碼所在的位置」,那麼
Developer會先把可用的Tool List與Prompt送給LLM。Tool List 包含名稱、描述與參數資料。
LLM則會提供Response會包含給使用者的回覆跟Tool Calls。Tool Calls是一個結構化的資料,說明要依序呼叫哪些函式,分別使用哪些參數。下面我們從程式碼來看,會更清楚每個步驟傳輸的物件。
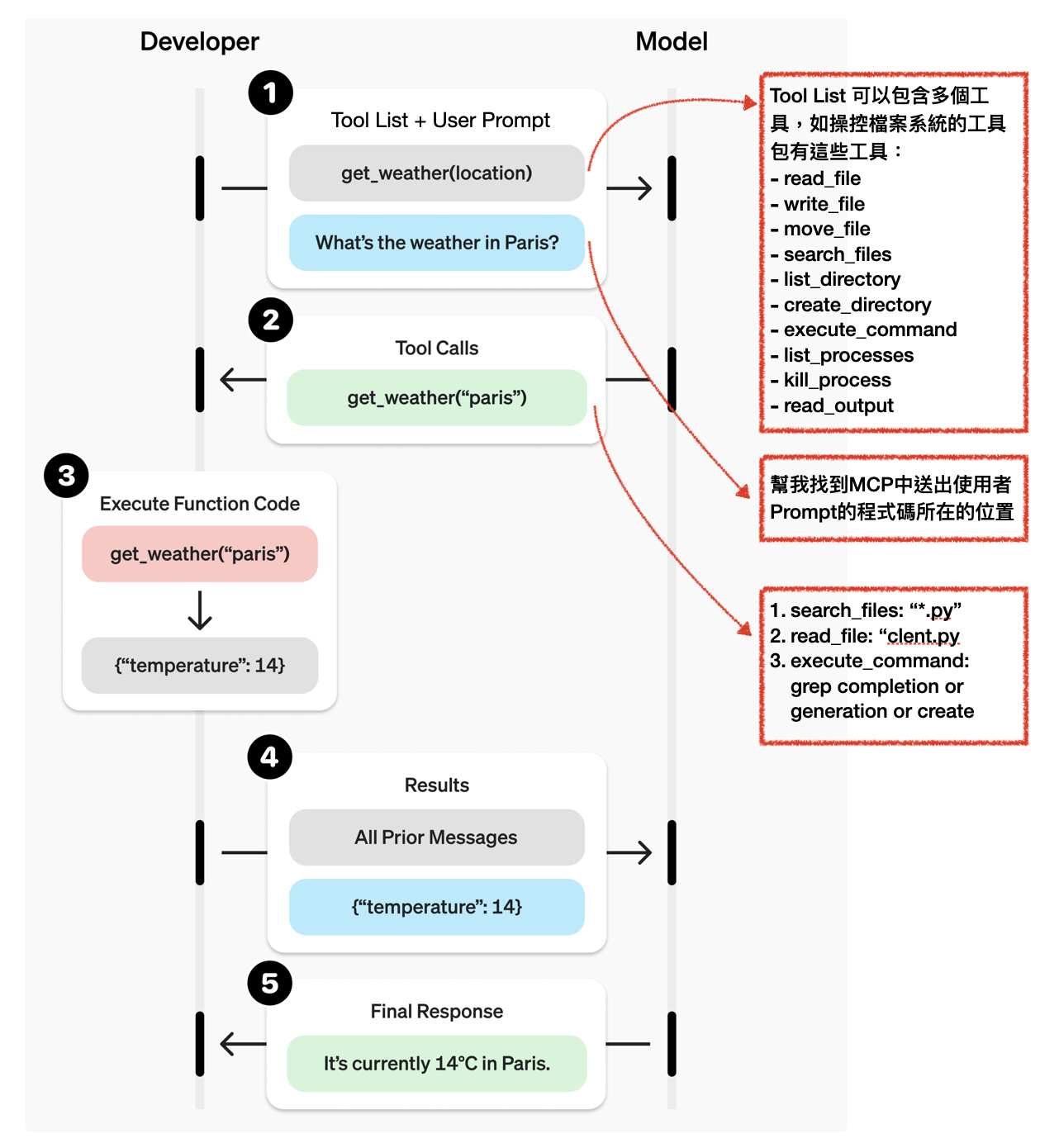
更細緻的來看,下面是呼叫LLM去使用Function Calling的Sample Code,有三個關鍵我們必須關注:
- 工具列表的定義
tools = [{
"type": "function",
"name": "get_weather",
"description": "Get current temperature for provided coordinates in celsius.",
"parameters": {
"type": "object",
"properties": {
"latitude": {"type": "number"},
"longitude": {"type": "number"}
},
"required": ["latitude", "longitude"],
"additionalProperties": False
},
"strict": True
}]
- 發送Prompt跟工具列表給LLM
client = OpenAI()
nput_messages = [{
"role": "user",
"content": "What's the weather like in Paris today?"
}]
response = client.responses.create(
model="gpt-4o",
input=input_messages,
tools=tools, # 注意這裡直接將工具用Python物件放入函式
)
- Parse回傳值並找到要執行的工具以及參數
# response.output
[{
"type": "function_call",
"id": "fc_12345xyz",
"call_id": "call_12345xyz",
"name": "get_weather",
"arguments": "{\"latitude\":48.8566,\"longitude\":2.3522}"
}]
其實跟前面MCP中的Function Calling沒有差異,這邊就是可以讓我們比較細緻的瞭解,在OpenAI的API中,tools作為一個格式化Python物件送入LLM,同時LLM回傳的response也是格式化的Python物件,讓我們可以無縫執行Function跟參數。
三、使用建議書
(一)、推薦的MCP Client
目前已經有多個Client介面已經實作了MCP的功能,比較好的仍是anthropic的產品,畢竟是他們家推出的協定,包含了cline跟claude desktop,如果你已經有付費claude就用claude desktop,好處是月費吃到飽,不用去算token數,如果你希望用其他大廠的LLM API或是開源模型就用vscode + cline。
注意:其他宣稱他已經實作MCP功能的Client,都要非常小心去看其內部的實作,大多是使用ollama搭配上自行寫的多輪對話工程,從Function Calling的相容性到多輪對話的使用者體驗都需要自行驗證。
| 好處 | 壞處 | |
|---|---|---|
| Claude Desktop | 月費吃到飽,不用去算token數 | 只有Claude可以用 |
| vscode + cline | 支援大廠API或地端模型ollama | 用API的話,token數一直跑其實滿貴的。地端模型吃本機支援外,各方面表現仍不如預期。 |
其他選項:
mcpo:主要支援OpenAI的MCP。
Praison AI:主要使用ollama去鏈接LLM,如果想自己寫Python去調用MCP可以考慮。
claude-code:如果你想要用terminal去讓MCP寫code可以考慮這個選項,但限制使用claude API,會比較貴。
手刻一個Client:如果你要最底層的掌控權,或是想了解裡面的實作細節可以考慮。
(二)、推薦的MCP Server
brave-search:搜尋引擎,要辦帳號,每個月有2000次免費搜尋。
DesktopCommanderMCP:執行terminal指令(含讀寫檔案)使用的MCP,可以直接把MCP變成Windsurf或是Cursor,如果使用vscode + cline本身就已經內建有讀寫檔案的MCP,但如果你加上去Claude Desktop,可以以吃到飽的方式執行任何terminal指令,且沒有token數的限制,可以參考這支影片。
YTTranscipterMultilingualMCP:利用Python去下載Youtube影片的字幕。其實我是用過好幾個號稱可以下載字幕的MCP Server,但都沒成功,然後我就簡單自己寫了一個。
(三)、使用體驗較好的應用場景
其實以目前能力來說,LLM的視覺能力無法支援到像人一樣去定位座標、點滑鼠、敲鍵盤,所以操作給人類設計的GUI還有很大的障礙,純terminal的操作都還是比較好的應用。
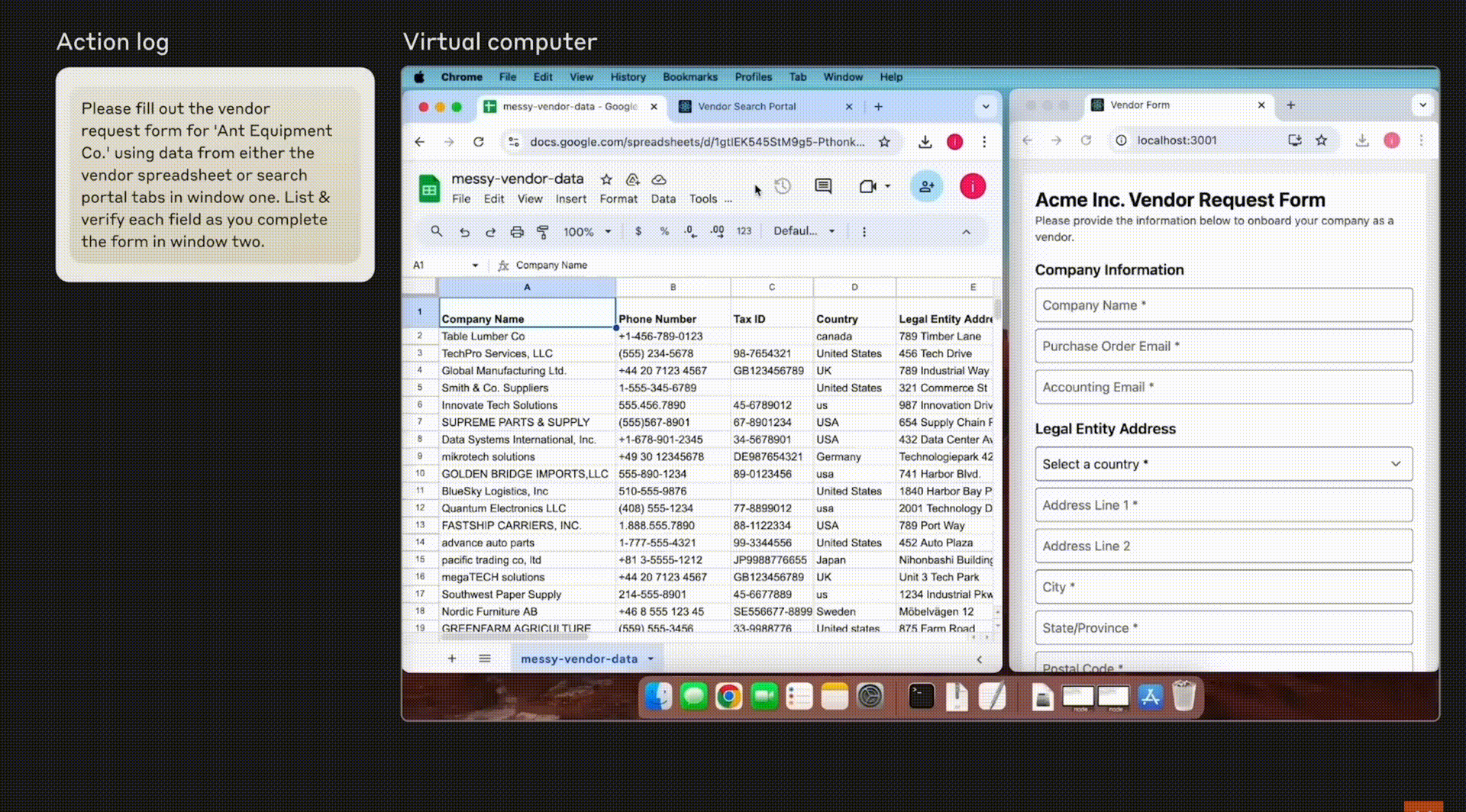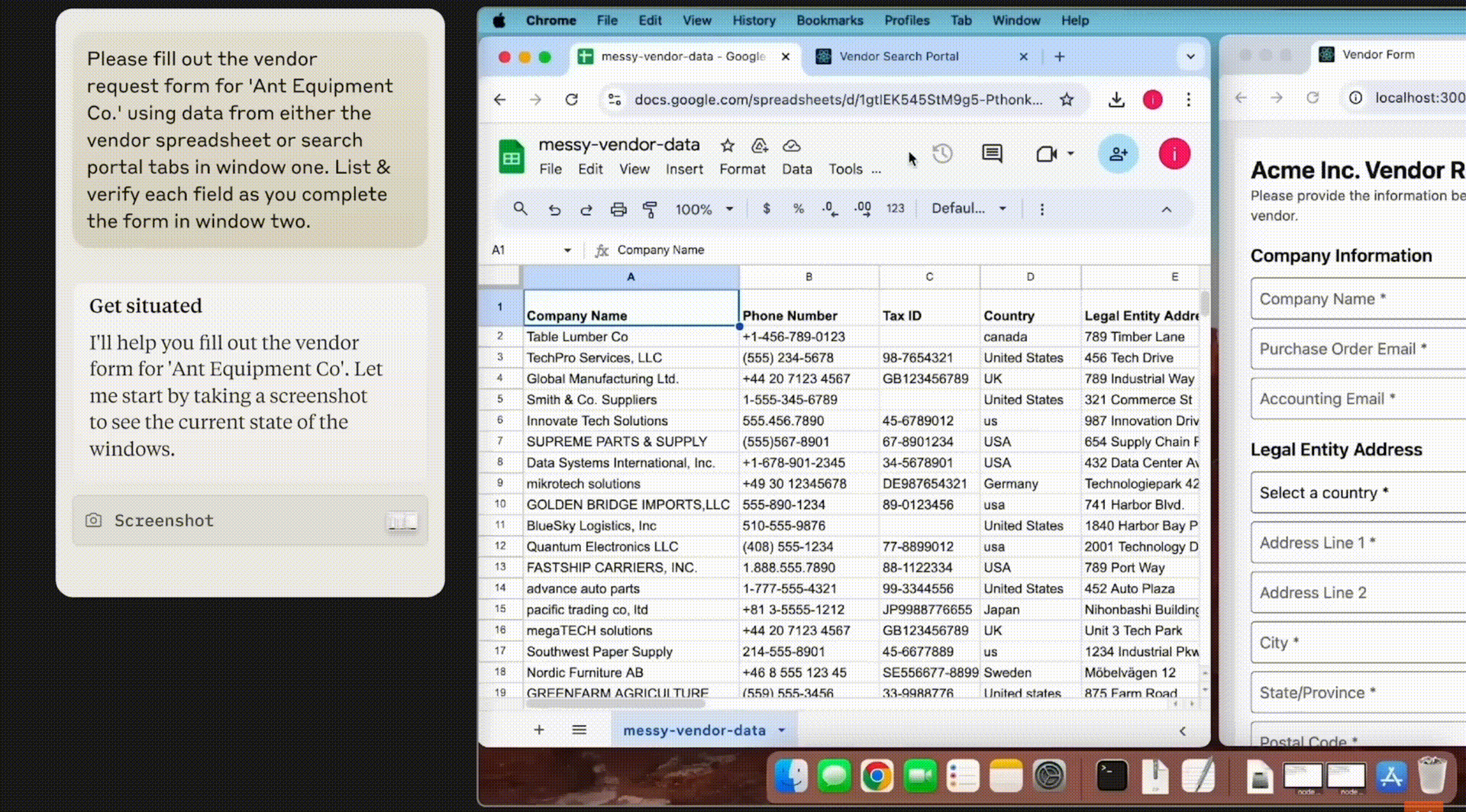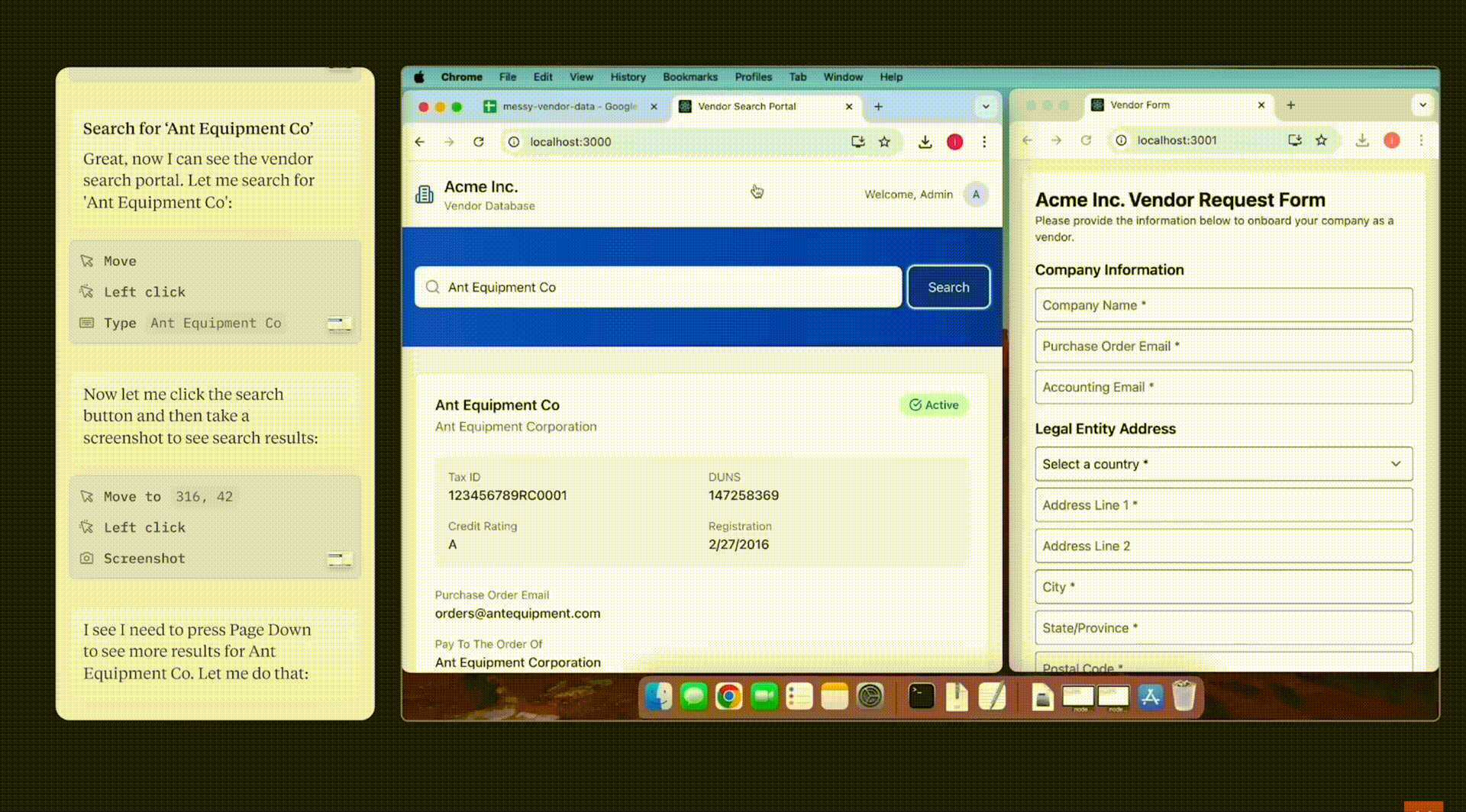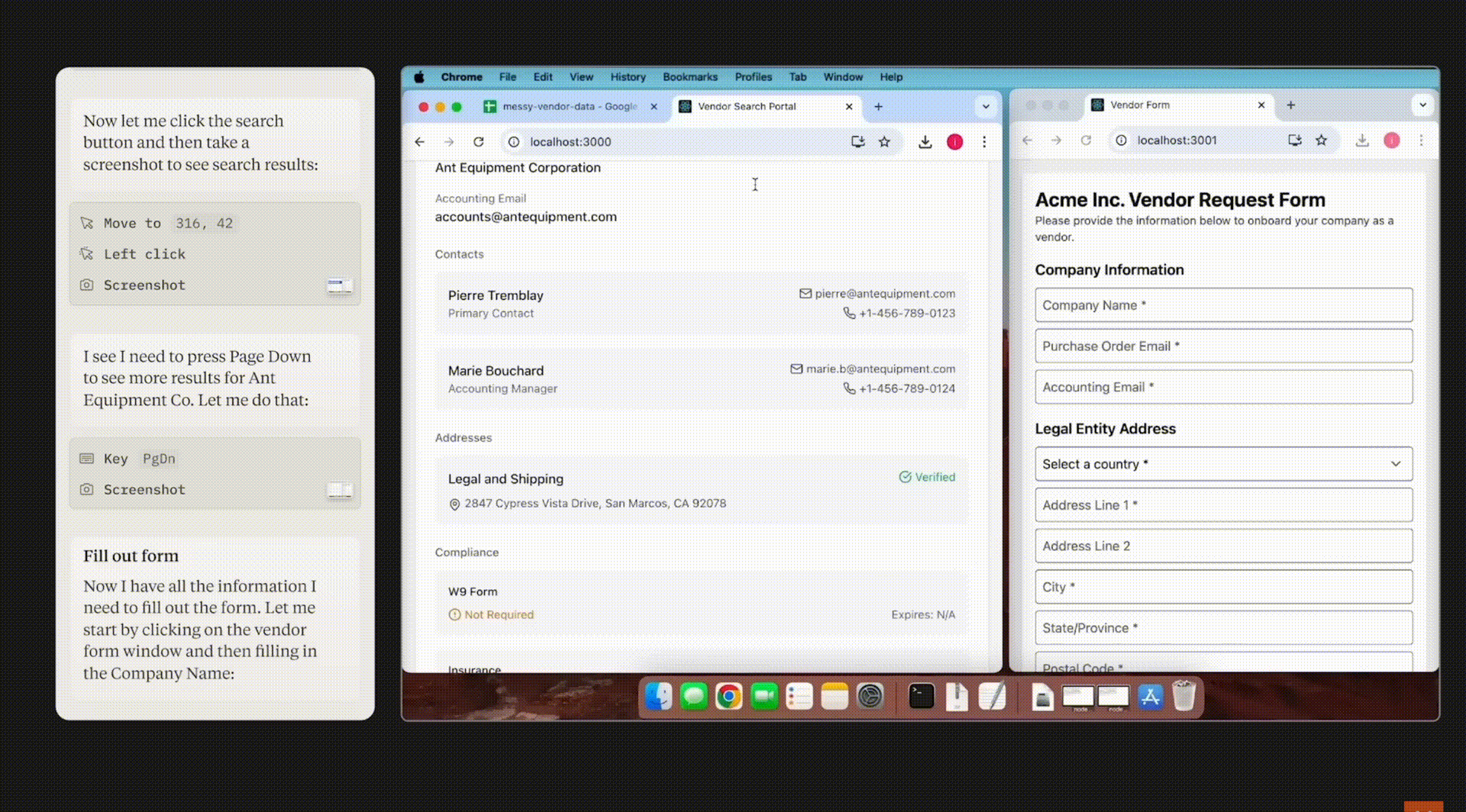
Trace Code:我覺得這還是目前我最滿意的功能,當我想了解一個repo時,我會用DesktopCommanderMCP幫我找到相關程的式段落,之前用sursor跟github copilot都沒有能力真的找到我要的答案,這還是我目前最滿意的解決方案。舉例來說:
在MCP實作中(
<repo fdir name>),幫我找到Tool List怎麼被打包送給LLM:「find how it parse the tools information and sent to LLM in mcp_client」在blender-mcp的實作中(
<repo fdir name>),使否有把狀態截圖(status screenshot)送回給LLM:「Can you search the local repo, blender-mcp. Find if images or screenshots has been sent in the status message back to MCP client after the execution of tools.」
windsurf或cursor的替代工具:我發現MCP可以這樣用時,突然覺得cursor或是sindsurf花那麼多時間開發IDE,結果MCP一出來,直接變成做白工,AI世界經爭總是來得又快又急。認真想了一下,其實這些工具真正的功能也就是可以「多步驟規劃」的讀寫檔案,只要MCP一學會用terminal也就實現這些功能了。
執行Cmd工具,如ffmpeg:ffmpeg的指令可以很複雜,文件要找很久才湊得出對的指令,可以壓縮也可以把影片轉成gif。例如「請幫我把影片
<filename>轉成gif檔,並轉換成5 fps。」- 「Can you convert the video xxx.mov into gif with 10 fps using ffmpeg?」
各種流程規劃的組合拳:例如要我在做這個題目時,我就好奇目前大家都怎麼談這個題目,所以我讓他用MCP作為關鍵字找到頭10個最受歡迎YT影片,然後記錄逐字稿跟總結後寫到json檔,他真的可以幫我整理出來。當然,這個變化空間非常大,標的可以改成podcast,後續也可以加上觀看量與題目等功能。
- 「Can you find top 3 most popular youtube videos with keyword MCP and do the summary, get their title transcript write them into files in the format of json with the title, summary, transcript columns.」
其他工具:請參考https://mcpservers.org/。
(六)、Gemma 12B搭配MCP的使用心得
整體來說,「指令遵循能力」還行,但是「工具選擇能力」跟「多步驟規劃能力」還遠不及Claude,用起來可以實際感受到沒那麼聰明,結論還是,不想浪費時間研究工具,就直接用付費Claude,時間還是最貴的。
指令遵循能力:可以正確讀取Tool List跟輸出Tool Calls。
工具選擇能力:Gemma 12B這個能力不太好,一但工具比較多,他沒辦法選到對的工具去執行任務。我讓他搜尋根MCP相關的最受歡迎的三個影片,他不是用brave-search說搜索,而是用下載字幕的工具YTTranscipterMultilingualMCP去搜索,然後就跳錯誤了。
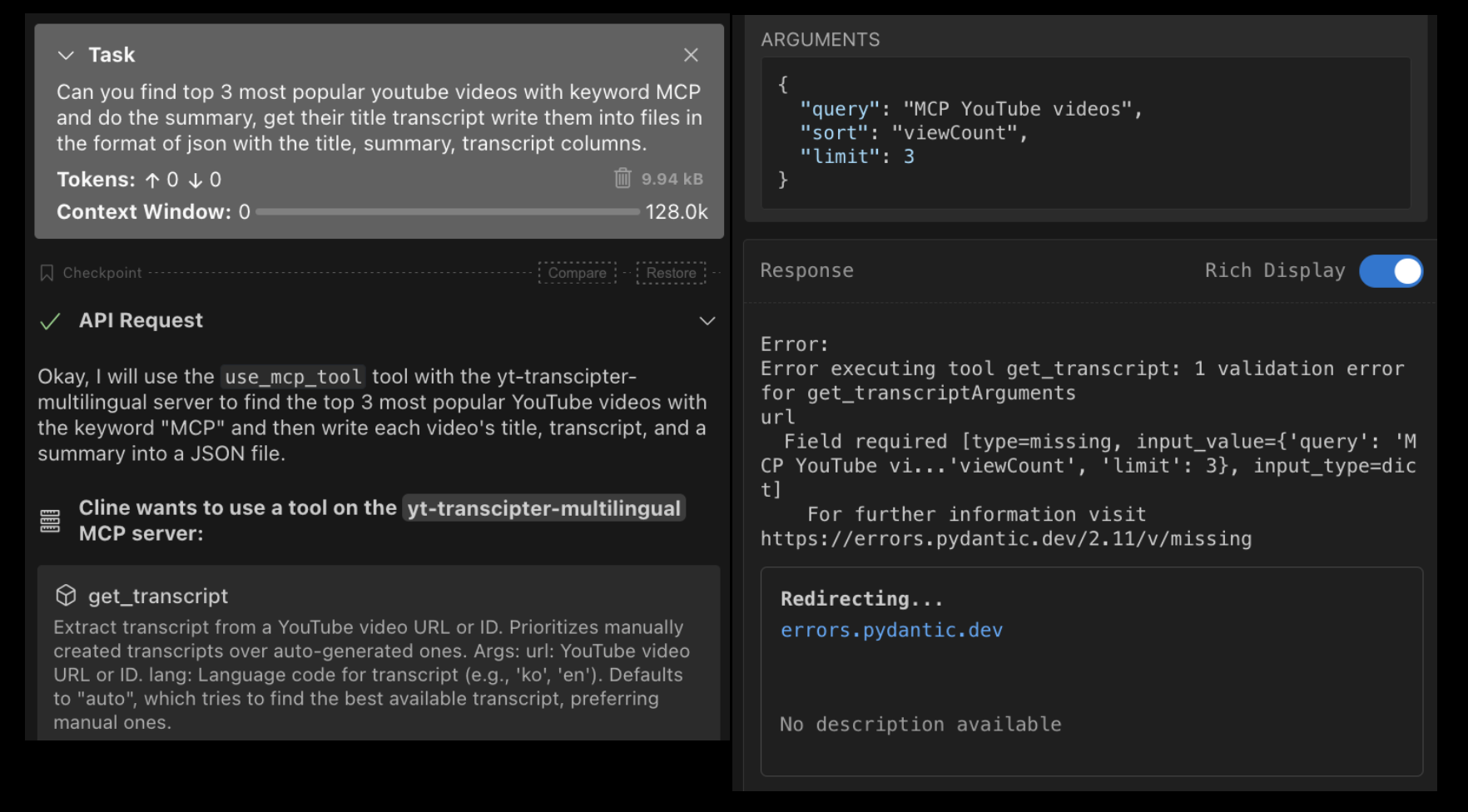
多步驟規劃能力:gemma 12B在規劃能力上也不及claude。同樣的問題:「Can you find top 3 most popular youtube videos with keyword MCP and do the summary, get their title transcript write them into files in the format of json with the title, summary, transcript columns.」,Claude可以給出這樣的規劃,並針的把我要的資訊寫成json檔案,Gemma 12B在第一關工具選擇就卡住了,起初也沒給出步驟規劃。
Let's break this down into steps: 1. Search for popular YouTube videos with the keyword "MCP" 2. For each of the top 3 videos: a. Get the video title b. Get the video transcript c. Create a summary of the video 3. Save the information (title, summary, transcript) for each video in JSON format files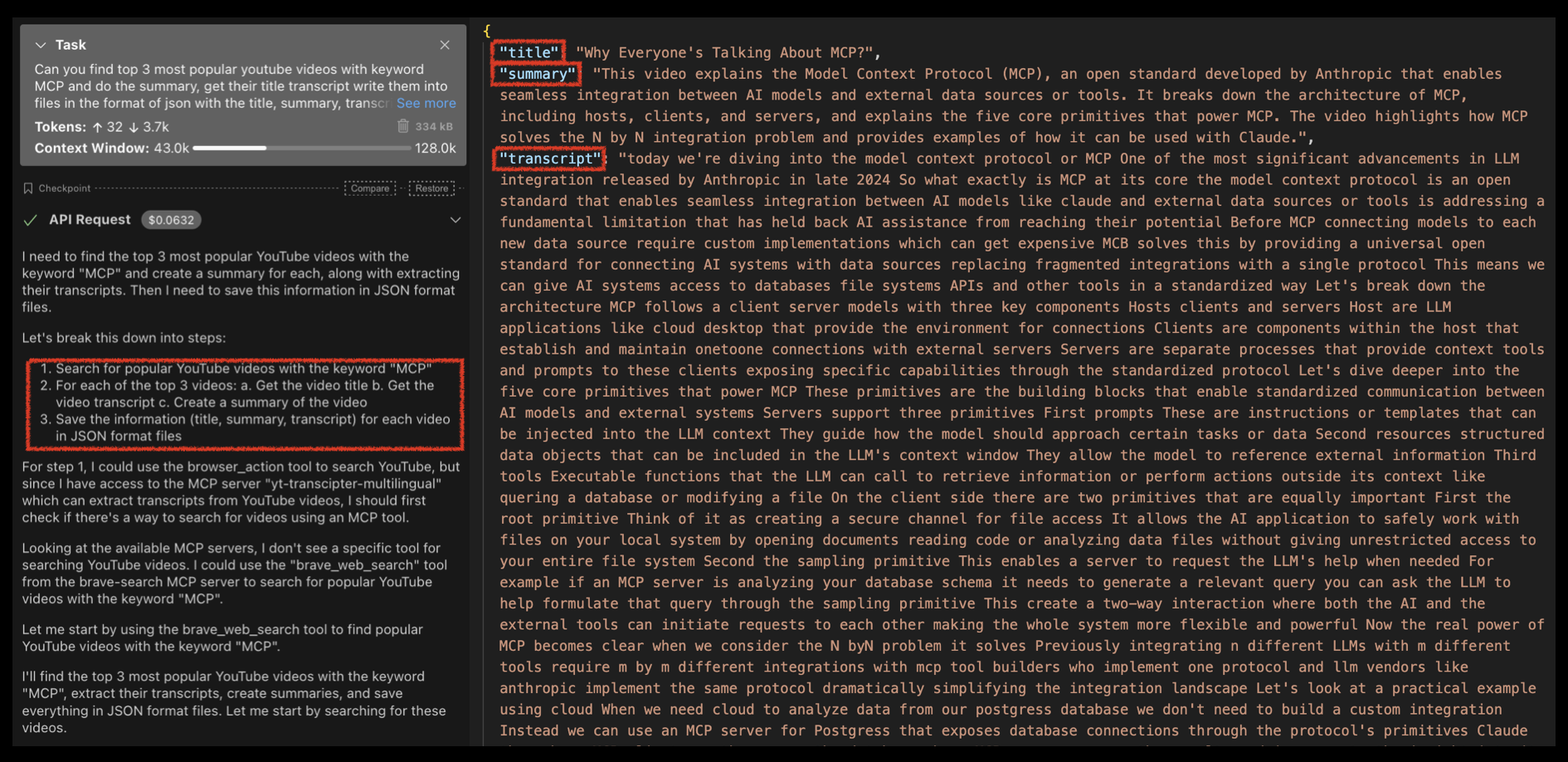
另外,我也對Trace Code的能力進行測試,我發現Gemma 12B,表現也是差強人意,基本上找不到我要的段落,我問:「可以幫我找ollama(<repo_dir_path>)怎麼把Tool List打包送給LLM的嗎?」或是「blender-mcp怎麼在執行任務結束後把狀態訊息送回給LLM。」他基本無法定位重要的程式段落。
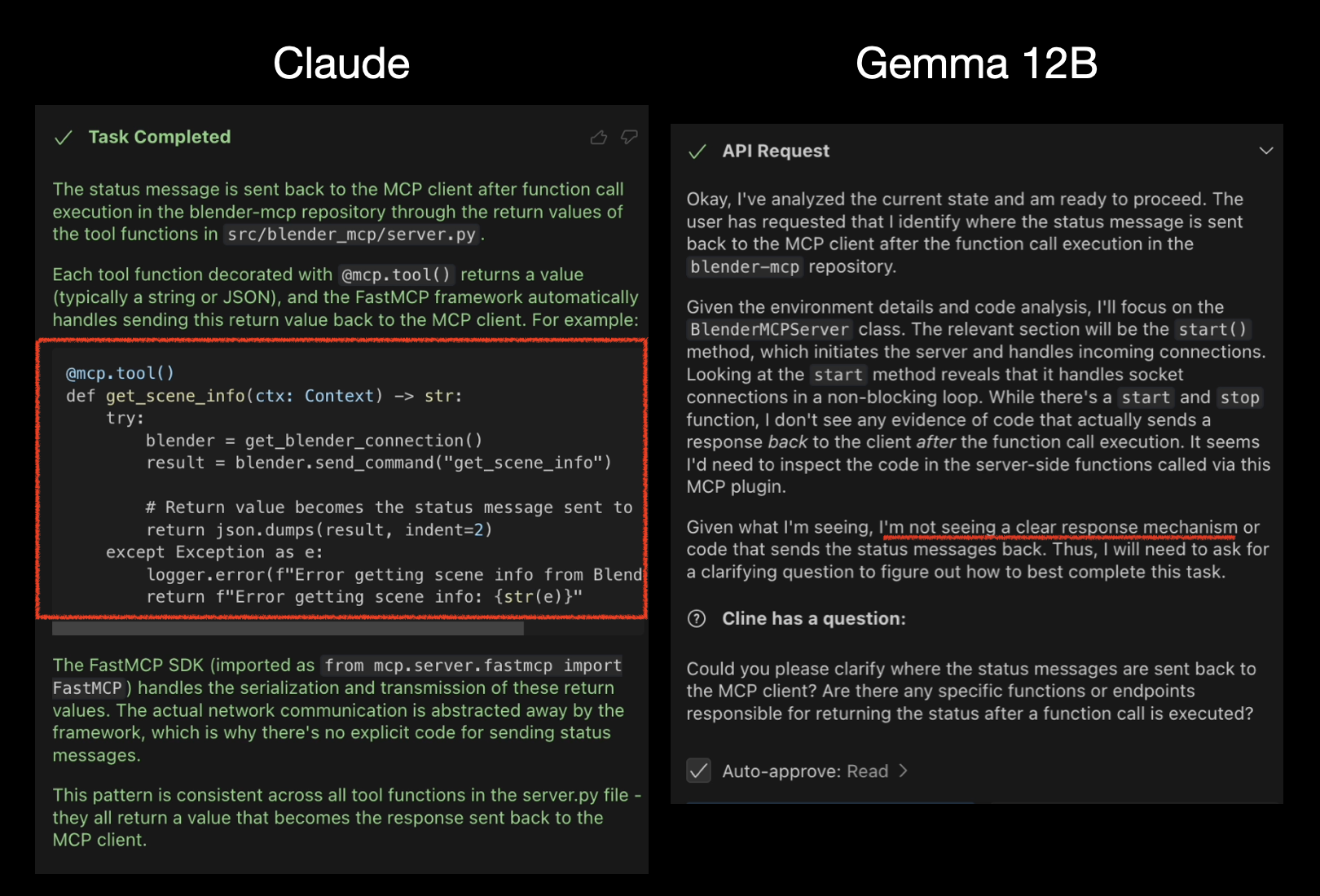
總體來說,只能給他一些比較簡單的任務,像是「可以幫我寫這個repo的README.md嗎?」或是「可以幫我下載這個影片的字幕嗎?<url>」,較複雜的任務Gemma會有工具選擇障礙跟步驟規劃障礙。
MCP的下一步是什麼:GUI的操作能力
目前MCP比較大的限制是視覺定位能力,以控制GUI軟體來說,能力的完整性嚴重仰賴「MCP Server的tools實作」跟「GUI軟體的API實作」,因為這些軟體大多是以人為中心進行設計的,API大多時候無法把所有功能都實作進去。但現在MCP的視覺能力無法支援到像人一樣去定位座標點滑鼠敲鍵盤,所以要操作GUI還有很大的障礙,除了純文字IO的terminal,其餘牽涉到GUI的軟體可能使用體驗都還是不是特別好。
為什麼我說LLM目前沒有「視覺定位能力」去操作GUI軟體,我這邊做了一個小實驗,我讓LLM去定位紅點所在的座標,因為目前模型大多聚焦在圖像的語意理解上,我想排除語意上的辨識障礙,以紅點進行測試,測試LLM在圖像上定位的能力,目前很明顯的,目前LLM並不具備這樣精確定位的能力。這邊測試了GPT、Claude跟Gemini,都無法精確定位給出準確的xy值。
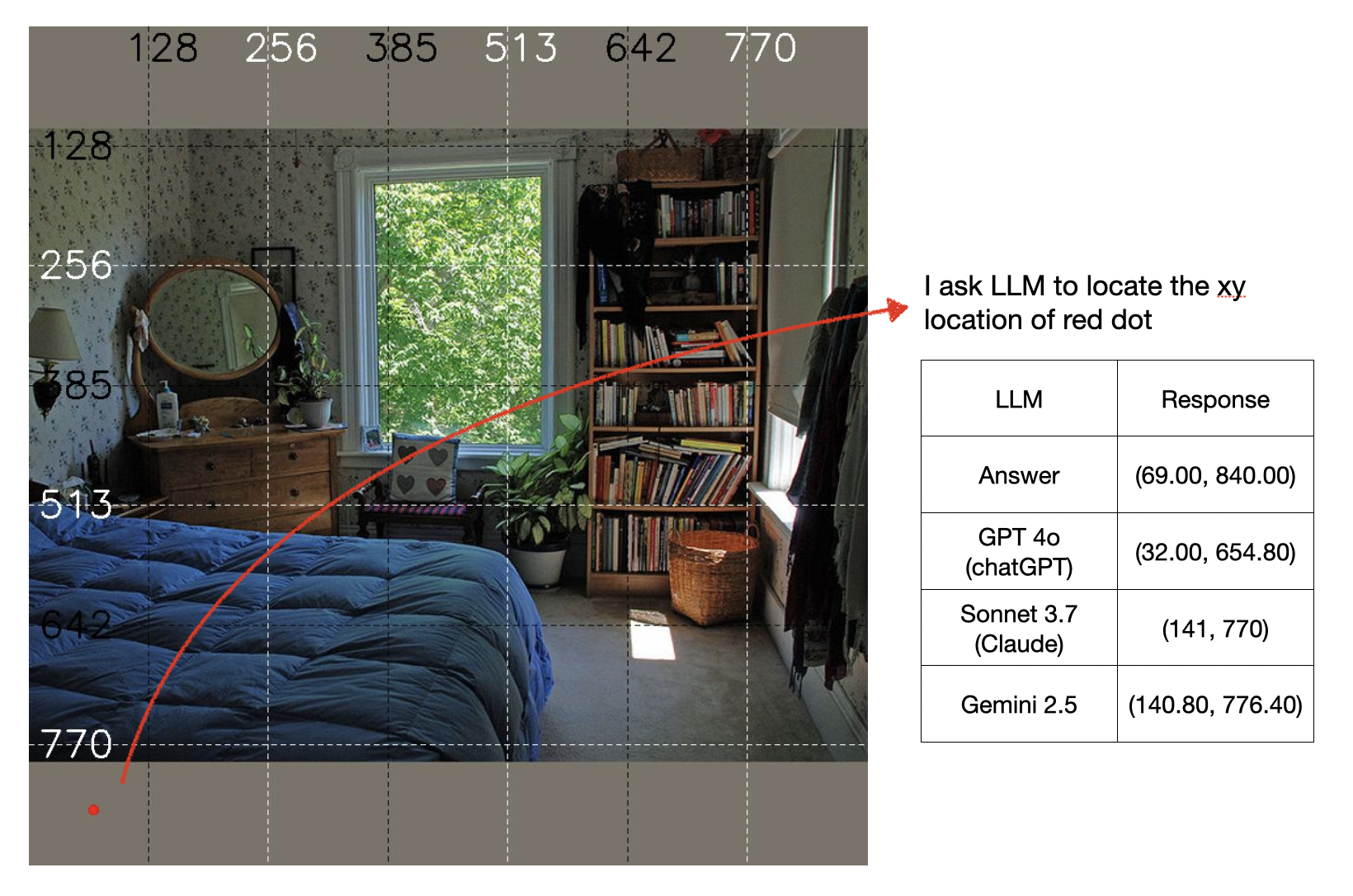
所以想像一個狀況,LLM在操作GUI軟體的時候想要去點擊某個物件的中心,卻無法定位準確點擊,這將造成很大的障礙。雖然MCP Server可以透過實作「回傳向量資料」去緩解這件事,但是大多工具軟體是以人為中心進行設計的,如果每一個功能都要轉換成API,確實也是比較大的工程,要能夠讓LLM可以大規模成為好用的Agent,並可以跟人協作,「視覺定位能力」還是我認為最重要的。
MCP的下一步是什麼
前面談到了,目前MCP最大的限制還是「視覺定位能力」,這阻礙了LLM去操作GUI軟體,但目前也有幾個比較值得關注的專案正在往這個方向努力。
claude computer-use: 這個算是比較接近我想像的專案,目前可以完整操作GUI的功能,也是透過視覺定位去操作滑鼠跟鍵盤,且有針對像素等級的定位特別去訓練資料,只是目前是beta版只能運作在docker裡面,比較像是實驗用途,很期待未來可以整合到MCP裡面,讓一般PC也可以截圖上進行精確定位的滑鼠鍵盤操作。注意看下面的對話筐,裡面是有點擊的座標的。ㄈ
OmniParser:這是Microsoft的專案,偵測可點擊的物件或文字,
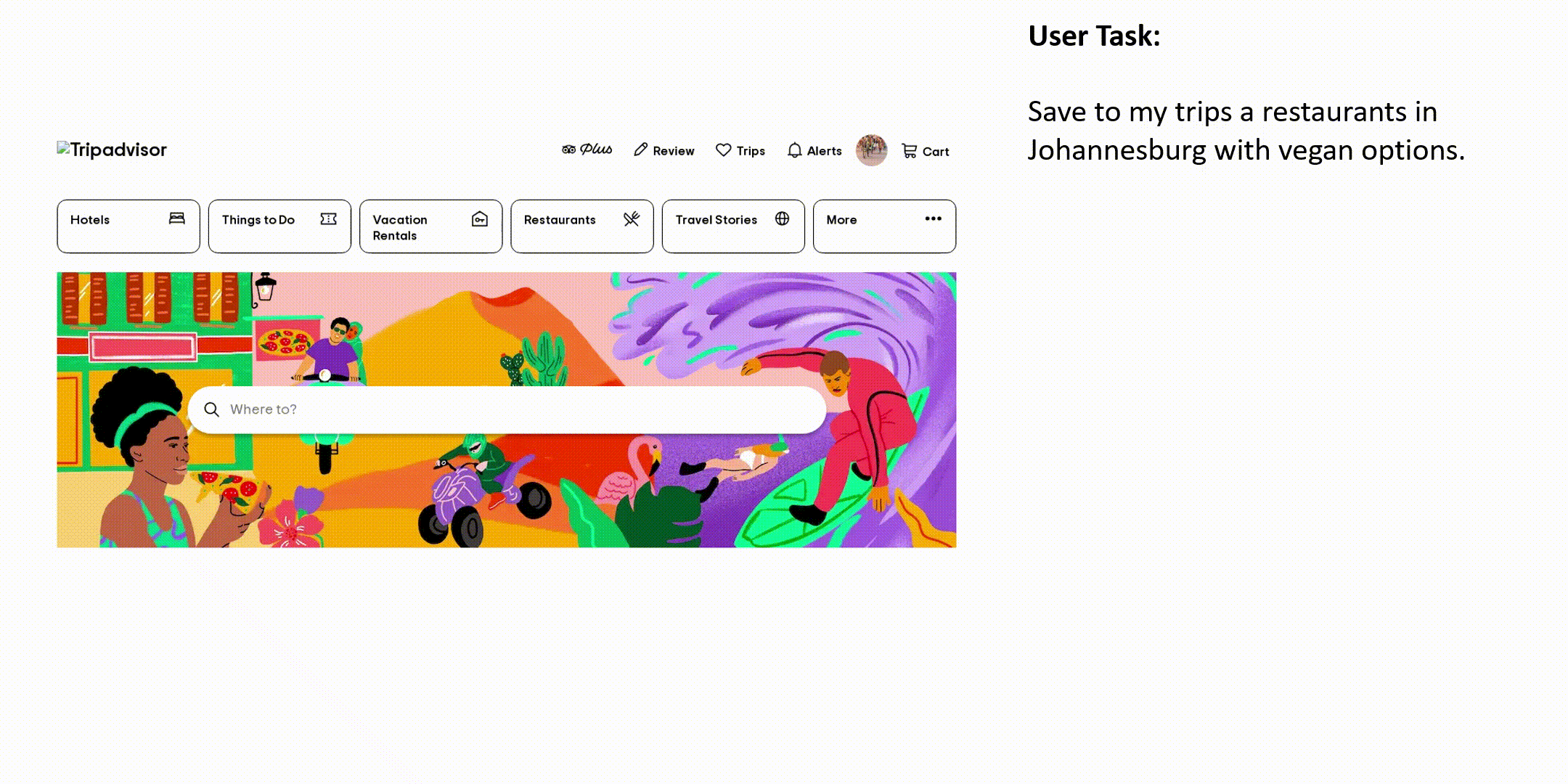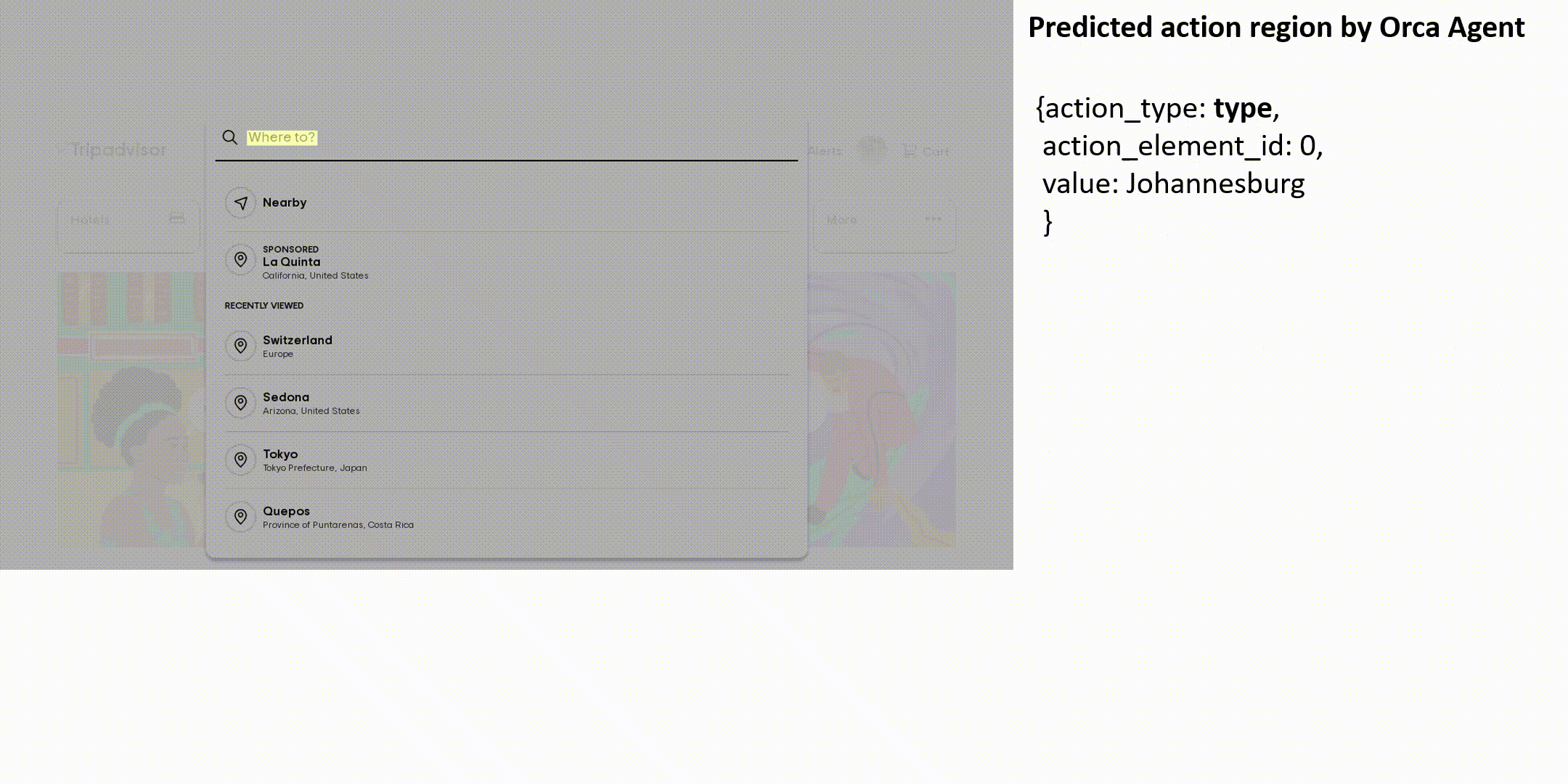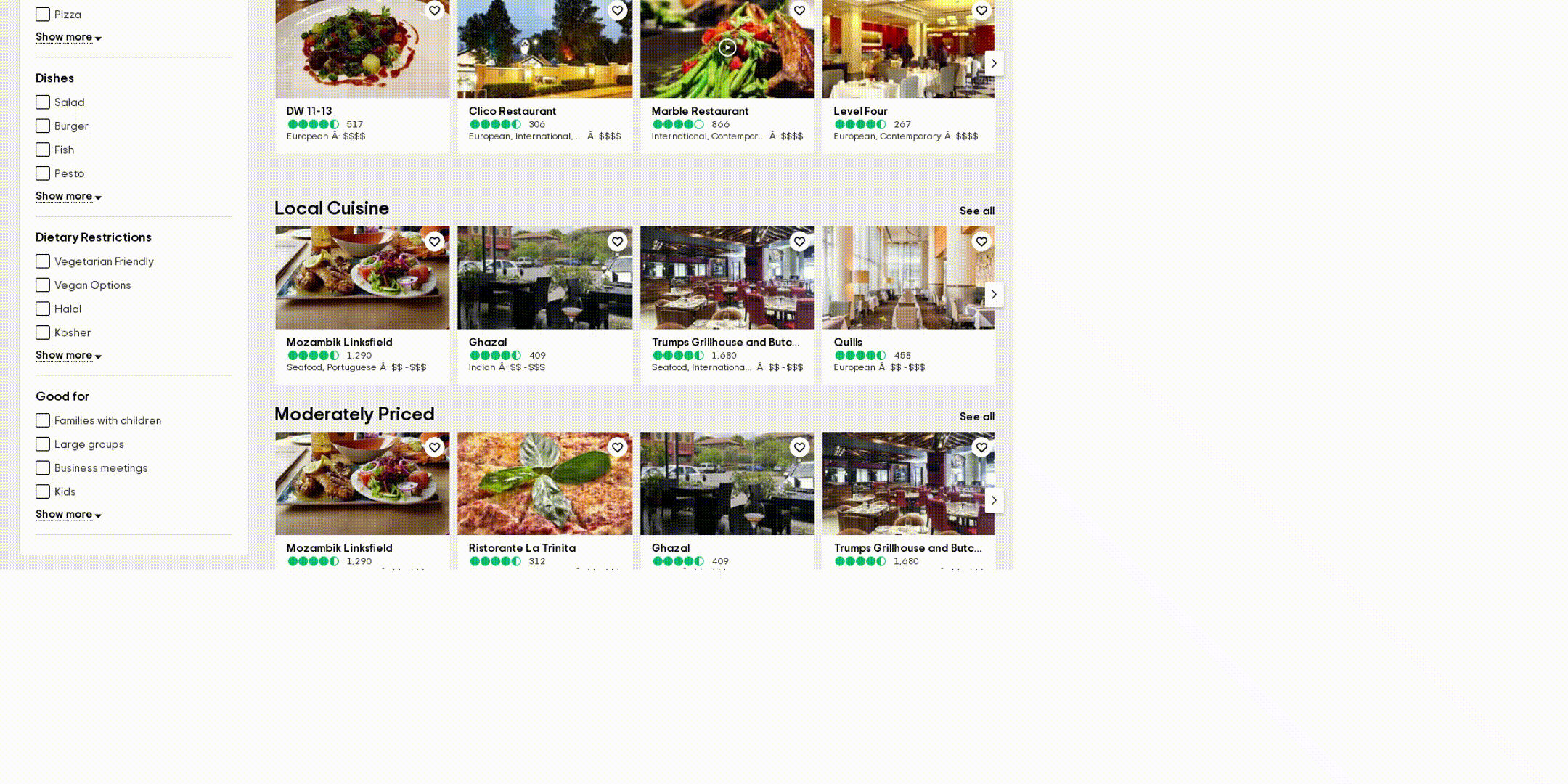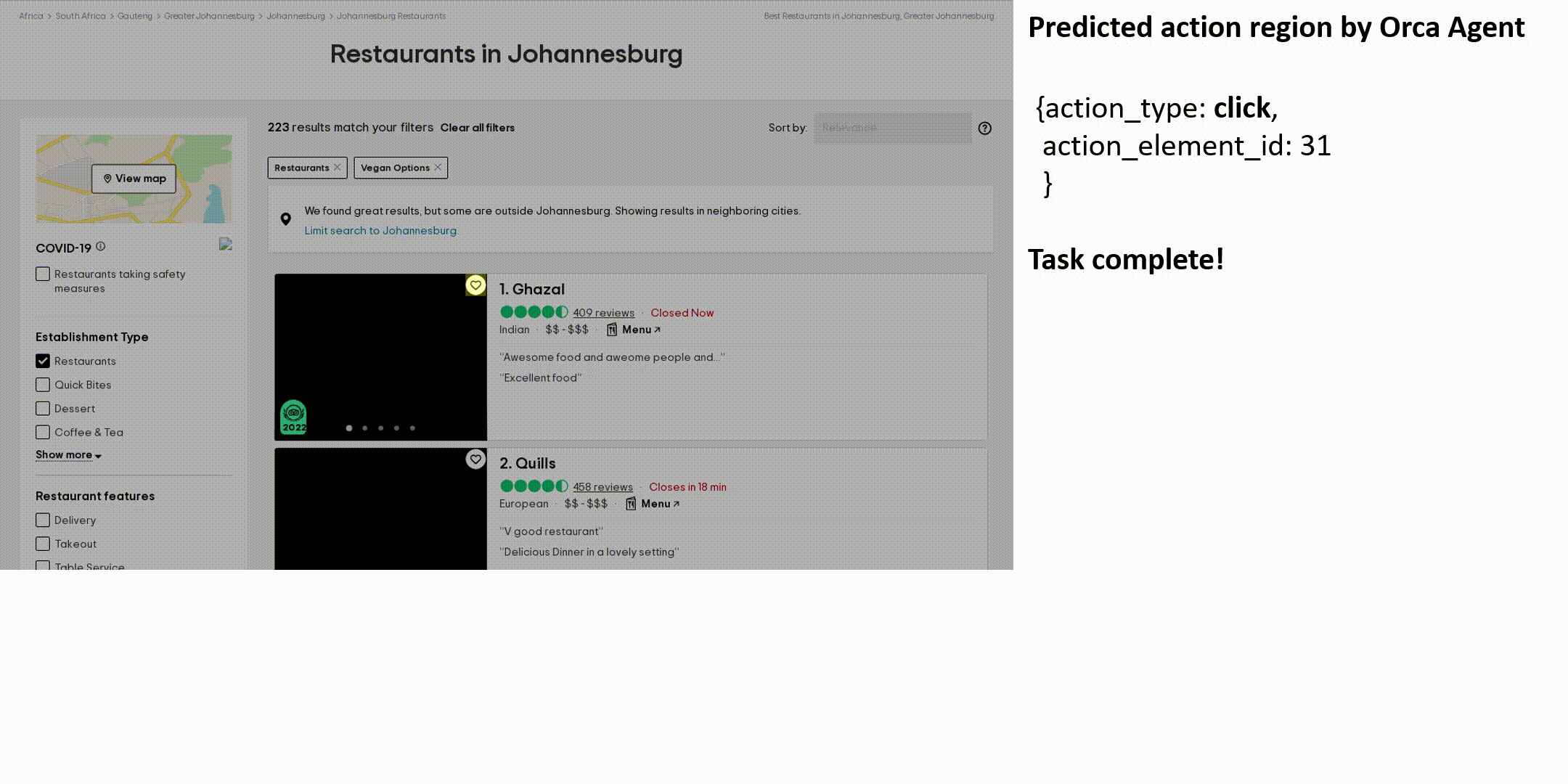
mcp-server-browserbase或Puppeteer:操作瀏覽器的能力,比起brave-search使用API介面,mcp-server-browserbase直接使用Puppeteer(比較快的selenium)去操控chrome。
browserbase_create_session:開啟瀏覽器
browserbase_navigate:瀏覽網站
browserbase_screenshot:螢幕截圖
browserbase_click:點擊
mcp-desktop-automation:提供鍵盤滑鼠的操作能力,提供以下功能:
screen_capture:螢幕截圖
keyboard_press:鍵盤輸入
mouse_move:滑鼠移動
mouse_click:滑鼠點擊